
Web scraping en Python
J'ai récemment eu besoin de faire du web scraping pour certains projets personnels. Ca m'a permis de me rendre compte à quel point cette pratique est puissante dès que l'on a besoin de données, ce qui m'a donné l'idée de faire cet article !
Nous allons dans un premier temps découvrir ce qu'est le web scraping, et nous verrons ensuite comment le mettre en pratique avec python.
- Table des Matières
Web scraping - qu'est-ce ?
Définition
Imaginez que vous ayez besoin d'une énorme quantité de données disponibles sur le web. Comment allez-vous récupérer ces données ? Peut-être en allant à la main sur chaque site web et en recopiant minutieusement les données dont vous avez besoin... Ou alors en écrivant un petit script de web scraping en python !
Applications
Le web scraping vous permet de parcourir automatiquement des pages web et d'en extraire le contenu dont vous avez besoin. Cela est peut-etre abstrait pour vous, alors en voici quelques applications :
- Extraction de données afin de les stocker dans vos propres bases de données.
- Comparaison de prix ou de produits.
- Collecte d'adresses mail.
- Statistiques (on a souvent besoin de très grandes quantités de données afin d'établir des statistiques précises).
- Et bien d'autres...
Pourquoi python ?
Python est très utilisé pour le web scraping. Mais pourquoi ? Il y a pourtant d'autres solutions, on peut penser notamment au javascript ou au C#.
Voici les principaux avantages de python pour le web scraping :
- Facilité d'utilisation : pas besoin d'avoir un code complexe pour faire des tâches complexes. Cela rejoint un autre avantage : il n'y a pas besoin de beaucoup de code pour réaliser des grosses tâches.
- Rapidité : le temps qu'on veut gagner grâce au web scraping, on ne veut pas le perdre en écrivant du code. Python nous permet de faire nos scripts très rapidement.
- Beaucoup de librairies : beaucoup de personnes ont déjà résolu les problèmes qu'on est susceptibles de rencontrer. C'est pourquoi python dispose d'un large panel de librairies pour à peu près tout, y compris le web scraping. Les deux principales sont notamment BeautifulSoup et Selenium.
- Une syntaxe facile à comprendre : cela rend l'écriture du code plus facile. Attention cependant, ce n'est pas parce que la syntaxe n'est pas complexe qu'il faut écrire du code de mauvaise qualité !
Les étapes du web scraping
On peut diviser le web scraping en plusieurs étapes :
- Collecte d'urls.
- Inspection des pages web afin de comprendre la structure du code source.
- Recherche de la donnée qui nous intéresse dans le code source.
- Ecriture du code.
- Collecte des données.
- Stockage des données dans un format adéquat.
Les librairies à utiliser
Comme je vous ai dit, on va utiliser BeautifulSoup et Selenium pour le web scraping.
BeautifulSoup permet des documents HTML et XML. Cette librairie représente les pages web sous forme d'arbre ce qui nous permet de récupérer très rapidement les données intéressantes.
Selenium permet d'automatiser des actions dans le navigateur web. En fait cette librairie nous permet d'émuler un navigateur web, et donc de récupérer du contenu généré dynamiquement (non récupérable avec BeautifulSoup), par exemple provenant de scripts javascript.
Exemple : scraping d'Amazon
Vous avez normalement compris ce qu'est le web scraping et à quoi il sert. On peut donc passer à un exemple. Nous allons voir comment scraper Amazon afin de récupérer des informations sur des produits. Par exemple, prenons le produit "clavier pc".
1. L'URL
La première étape comme nous avons vu plus haut, est de récupérer l'URL qui nous intéresse. On va aller sur Amazon, et on va tapper "clavier pc" dans la barre de recherche. On valide. J'obtiens cet url : https://www.amazon.fr/s?k=clavier+pc&__mk_fr_FR=%C3%85M%C3%85%C5%BD%C3%95%C3%91&crid=16O7KQHGZ876R&sprefix=clavier+pc%2Caps%2C63&ref=nb_sb_noss_1
2. Inspection de la page web
En deuxième étape, on va inspecter la page web pour comprendre le code source. Pour cela, on clique droit n'importe où sur la page, et on clique sur "inspecter l'élément". Cela nous ouvre l'inspecteur d'éléments du navigateur. Normalement votre fenêtre ressemble à ça maintenant :
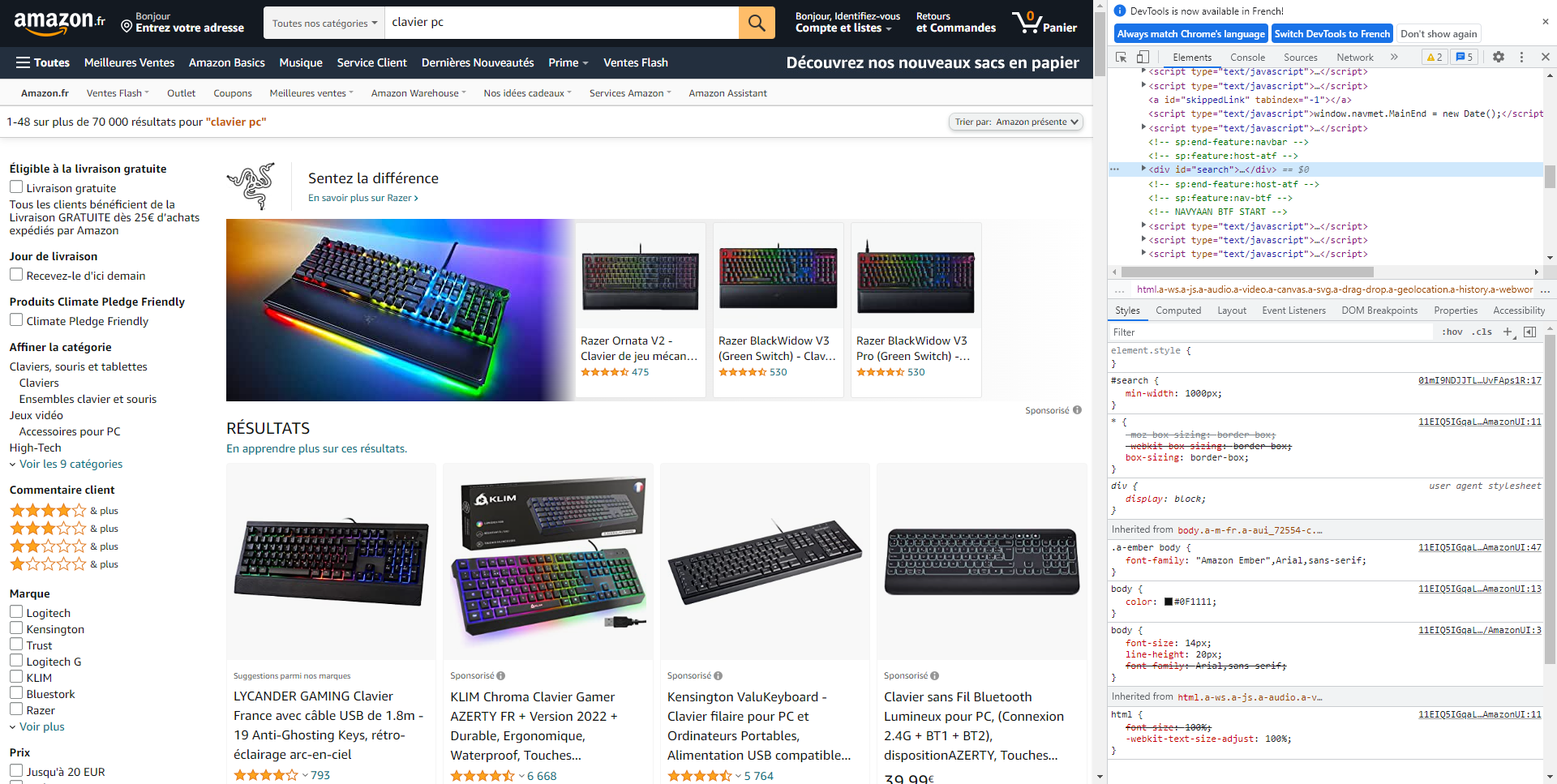
3. Recherche des données dans le code source
Pour rechercher les données qui nous intéressent dans le code source, il nous suffit de cliquer sur un élément de la page et l'élément HTML correspondant va s'ouvrir dans l'inspecteur d'éléments. On va essayer de sélectionner l'ensemble de la section d'un produit, comme dans l'image suivante :
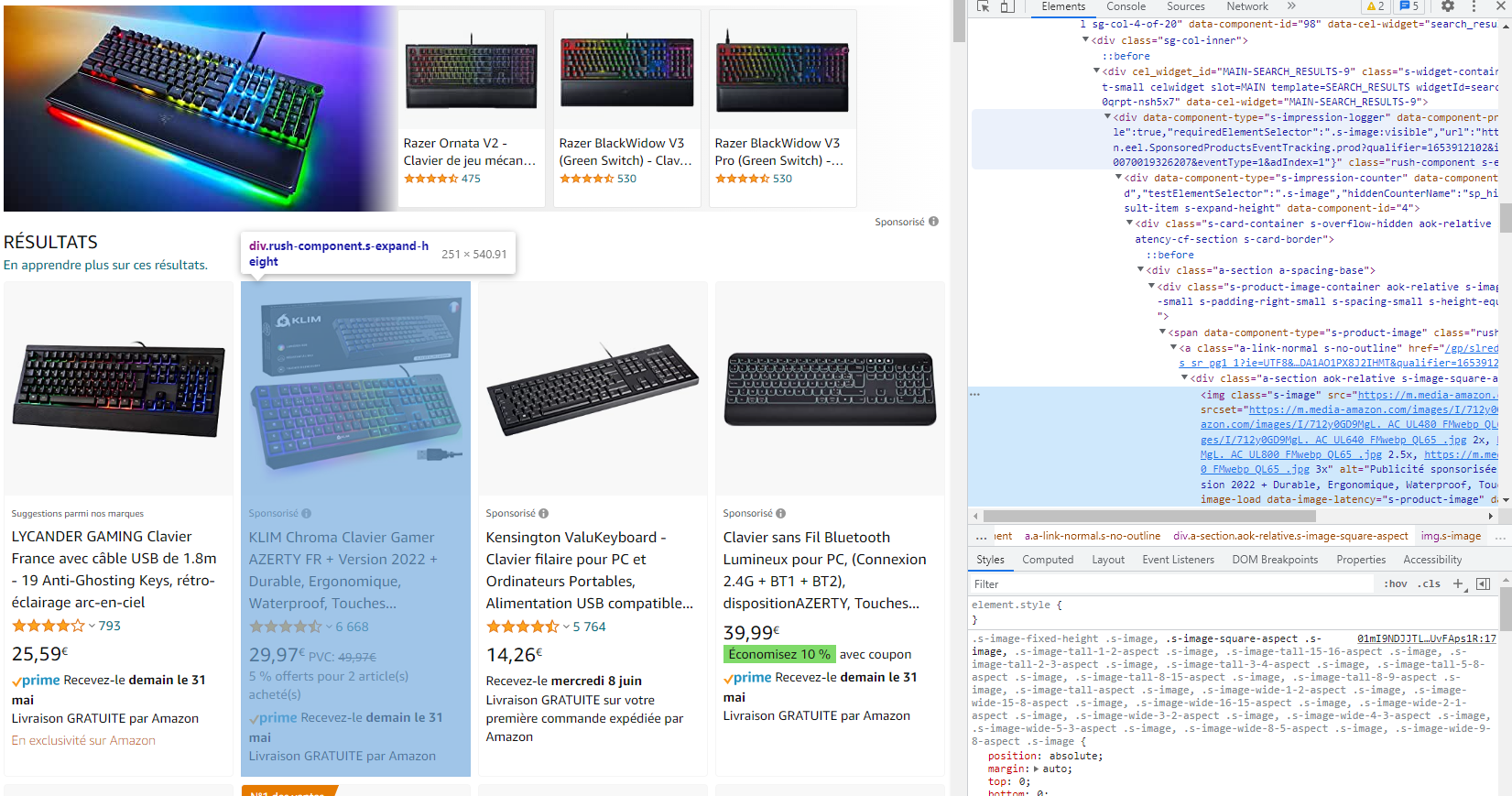
On note bien la classe de la section : "rush-component s-featured-result-item s-expand-height". On retient aussi le tag html : "div".
On fait pareil pour le titre : "span.a-size-base-plus a-color-base a-text-normal". Au passage on regarde aussi pour le lien associé au titre : "a.a-link-normal s-underline-text s-underline-link-text s-link-style a-text-normal".
On va aussi prendre la note sur 5 étoiles : "span.a-icon-alt".
Et finalement le prix : "span.a-price-whole".
4. Ecriture du code
On va maintenant pouvoir passer au code ! La première chose à faire est d'installer les drivers pour faire fonctionner Selenium avec votre navigateur web.
Pour le coup je ne peux pas vous aider, cela dépend de votre navigateur. Si vous êtes sous Chrome, vous trouverez les drivers ici : ChromeDrivers. Il faut prendre celui qui correspond à votre version de Chrome.
Maintenant que c'est fait, on peut créer un nouveau projet, et mettre le driver à la racine (où n'importe où ailleurs).
Une fois cela fait, on peut coder. On commence par les imports :
from selenium import webdriver
from bs4 import BeautifulSoupOn initialise maintenant notre driver en précisant en paramètre le chemin pour y accéder. S'il est à la racine, on n'a pas besoin de passer ce paramètre :
driver = webdriver.Chrome("C:/Users/me/webdrivers/chromedriver")Ensuite, on se dirige vers l'url qu'on a noté plus haut avec le driver :
url = "https://www.amazon.fr/s?k=clavier+pc&__mk_fr_FR=%C3%85M%C3%85%C5%BD%C3%95%C3%91&crid=16O7KQHGZ876R&sprefix=clavier+pc%2Caps%2C63&ref=nb_sb_noss_1"
driver.get(url)
Normalement le driver arrive sur la bonne page, mais il faut d'abord cliquer sur le bouton pour accepter les cookies.
Pour que le driver clique dessus, il faut dans un premier temps récupérer l'élément du bouton, et ensuite lui dire de cliquer dessus.
On repère donc le code source qui correspond au bouton, et on trouve son id : sp-cc-accept.
Pour récupérer le bouton à partir du driver, on utilise find_element :
from selenium.webdriver.common.by import By
cookie_btn = driver.find_element(By.ID, 'sp-cc-accept')Déjà, on import By. C'est une énumération qui nous permet de définir la méthode de recherche de nos éléments. Ici par exemple, on souhaite rechercher avec l'id, donc on utilise By.ID.
find_element prend un deuxième paramètre, qui est la valeur que l'on recherche. Ici, l'id du bouton est "sp-cc-accept", donc on renseigne en valeur sp-cc-accept. Cette méthode nous renvoie un objet selenium avec lequel on peut interagir. Cette méthode ne renvoie qu'un seul élément qui est le premier trouvé, si on avait voulu renvoyer tous les éléments correspondants à nos critères on aurait utilisé find_elements.
Ainsi, pour cliquer sur le bouton une fois qu'on a récupéré l'élément correspondant, il suffit de faire :
cookie_btn.click()Bien, maintenant quand on exécute sur notre script on arrive sur la page avec nos produits. Ce qu'on va faire, c'est récupérer le code source de la page et commencer à utiliser BeautifulSoup pour l'analyser.
content = driver.page_source
soup = BeautifulSoup(content)
diver.page_source permet de récupérer le code source de la page, et BeautifulSoup(content) renvoie un objet permettant de l'analyser.
Pour analyser le code source, on dispose de 2 méthodes : find et find_all. find ne renvoie qu'un seul élément correspondant au premier élément trouvé, et find_all renvoie tous les éléments, c'est identique à selenium.
Ces deux méthodes prennent en premier paramètre le tag html de l'élément qu'on cherche (span, div, a, etc...), et prennent un paramètre optionnel attrs qui est un dictionnaire d'attributs permettant de définir des critères de recherche. Regardez un exemple pour trouver tous les span qui ont la classe "little-text" :
elements = soup.find_all('span', attrs: {'class': 'little-text'} Normalement c'est plus parlant comme ça. Revenons à notre exemple. On va commencer par récupérer toutes les div de nos produits, et ensuite pour chaque div on récupérera le titre, le prix, le lien et la note. On a déjà repéré les classes à utiliser pour séléctionner nos éléments, ça donne donc ceci (essayez de le faire par vous-mêmes d'abord hein) :
for div in soup.find_all('div', attrs={'class': 'rush-component s-featured-result-item s-expand-height'}):
title = div.find('span', attrs={'class': 'a-size-base-plus a-color-base a-text-normal'})
link = div.find('a', attrs={'class': 'a-link-normal s-underline-text s-underline-link-text s-link-style a-text-normal'})
note = div.find('span', attrs={'class': 'a-icon-alt'})
price = div.find('span', 'a-price-whole')5. Collecte des données
Bon, on va stocker tout ça dans des listes. On les initialise avant notre boucle for :
titles = []
links = []
notes = []
prices = []
Et notre boucle for devient :
for div in soup.find_all('div', attrs={'class': 'rush-component s-featured-result-item s-expand-height'}):
title = div.find('span', attrs={'class': 'a-size-base-plus a-color-base a-text-normal'})
link = div.find('a', attrs={'class': 'a-link-normal s-underline-text s-underline-link-text s-link-style a-text-normal'})
note = div.find('span', attrs={'class': 'a-icon-alt'})
price = div.find('span', attrs={'class': 'a-price-whole'})
titles.append(title.text)
links.append(link['href'])
if note:
notes.append(note.text)
else:
notes.append('Aucune note')
prices.append(price.text)
Remarquez que je récupère l'attribut text de certains éléments. Sinon ce sont des éléments html et ce n'est pas ce qui nous intéresse. Essayez de les afficher sans récupérer le texte et vous verrez.
Pour les liens, je récupère l'attribut html href qui correspond à l'adresse du lien. En récupérant l'attribut text, j'aurai récupéré le texte du lien et ce n'est pas ce qui m'intéresse.
Certains produits n'ont pas de note, c'est pour ça que j'ai fait une petite vérification avant d'ajouter une note à la liste.
6. Stockage
Bien, maintenant il ne nous reste plus qu'à stocker tout ça. On va tout mettre dans un fichier csv. Pour cela on va utiliser Pandas. Si vous ne savez pas utiliser Pandas, j'ai déjà fait plusieurs articles dessus, n'hésitez-pas à aller les voir.
import pandas as pd
df = pd.DataFrame({'Nom':titles,'Prix': prices,'Note': notes, 'Lien': links})
df.to_csv('produits.csv', index=False)
On crée un DataFrame de nos produits, et on l'enregistre en csv.
Et voilà !
Voici à quoi ressemble mon fichier csv :
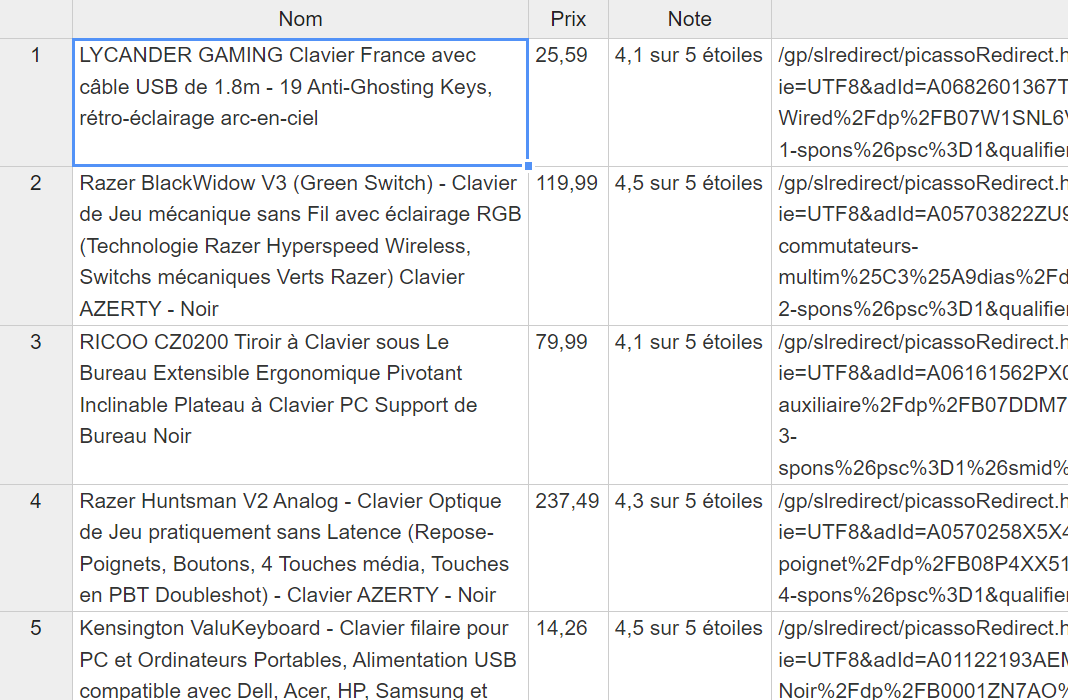
Le mot de la fin
On a pu voir avec un exemple très simple comment extraire des données sur internet. Vous avez pas mal d'outils pour débuter avec cet article, à vous de vous renseigner sur les portes que ça vous ouvre. Pour vous donner quelques idées, j'ai déjà eu l'occasion de copier la base de données d'un site web, d'optimiser du référencement naturel, de récupérer des données sur des sites ne proposant pas d'API, etc...
Si vous avez des questions ou que vous souhaitez me faire un retour, n'hésitez pas à me contacter par mail ou à laisser un commentaire.
On se retrouve prochainement pour voir des applications un peu plus avancées du webscraping !